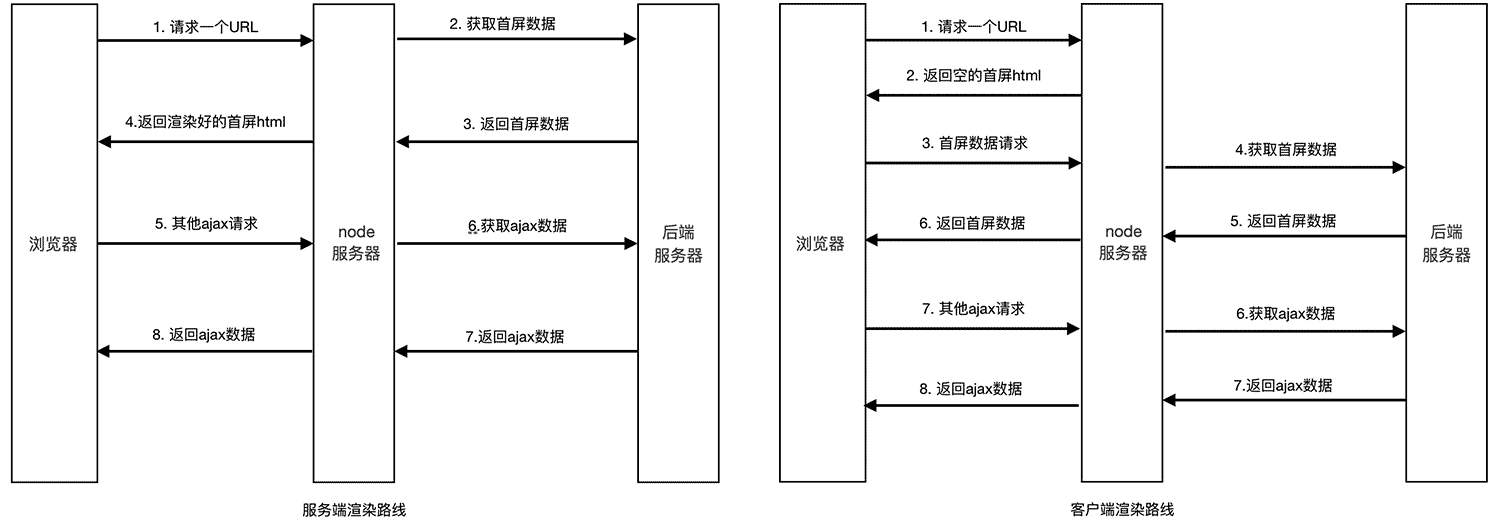
正则表达式(Regular Expression)是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合验证用户给出的指定字符是否合规的一种手段。正则表达式在几乎所有语言中都可以使用,各语言间略有差别,但大体上是一致的。这里简单整理下常用正则的使用方法。

规则
元字符
- \ : 转义字符
- ^ : 匹配字符串的开始
- $ : 匹配字符串的结束
- . : 匹配除 \n 和 \r 外的单字符
- \0 : 匹配空(NULL)字符(U+0000)
- \n : 匹配换行符(U+000A)
- \f : 匹配分页符(U+000C)
- \r : 匹配回车符(U+000D)
- \v : 匹配垂直制表符(U+000B)
- \t : 匹配水平制表符(U+0009)
- \w : 匹配字母、数字、下划线或汉字的字符
- \W : 匹配任意非字母、数字、下划线或汉字的字符
- \s : 匹配任意空白符的字符
- \S : 匹配任意非空白符的字符
- \d : 匹配数字字符
- \D : 匹配任意非数字字符
- \b : 匹配单词的开始或结束
- \B : 匹配非单词开始或结束位置
- \uxxxx : 匹配十六进制 Unicode 字符
- [\b] :匹配退格符(U+0008)
- [abc] : 匹配 abc 代表的字符
- [^abc] : 匹配非 abc 代表的字符
- [a-g] : 匹配 a 到 g 间的字符
运算符
- () : 分组,小括号内为一组
- | : 条件或,满足任意条件即通过
- [] : 匹配区间,
数量词
- * : 匹配任意多次,等价{0,},注意这里转义了,没有左侧斜杠
- + : 匹配至少一次,等价{1,},注意这里转义了,没有左侧斜杠
- ? : 匹配最多一次,等价{0,1}
- {n} : 匹配 n 次,非负整数
- {n,} : 匹配至少 n 次,非负整数
- {n,m} : 匹配 n 到 m 次,非负整数
- *? : 惰性匹配,可以重复任意多次,但尽可能匹配重复少的
- +? : 惰性匹配,可以重复至少一次,但尽可能匹配重复少的
- ?? : 惰性匹配,可以重复最多一次,但尽可能匹配重复少的
- {n,}? : 惰性匹配,可以重复至少 n 次,但尽可能匹配重复少的
- {n,m}? : 惰性匹配,可以重复 n 到 m 次,但尽可能匹配重复少的
断言
- a(?=b) : 先行断言,a 只有在 b 前面才匹配
- a(?!b) : 先行否定断言,a 只有不在 b 前面才匹配
- (?<=b)a : 后行断言,a 只有在 b 后面才匹配
- (?<!b)a : 后行否定断言,a 只有不在 b 后面才匹配
修饰符
- i : 执行对大小写不敏感的匹配
- g : 执行全局匹配,默认匹配首个
- m : 执行多行匹配,默认单行匹配 Multiline
- u : 开启 Unicode 模式,处理 UTF-16 编码字符
- s : 允许匹配换行符
- y : 执行全局匹配,但需要粘连
工具
桌面工具 >>> RegexBuddy
在线调试 >>> regex101
常用
电话号码
- 国际 : ("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX)
^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$ - 国内 : (021-87888822、0511-4405222)
\d{3}-\d{8}|\d{4}-\d{7}
手机号码
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
电子邮箱
^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
身份证号
^\d{15}|\d{18}$
IP 地址
((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))
网站域名
[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
日期格式
^\d{4}-\d{1,2}-\d{1,2}